This article is the final submission in a 3-part series which uses probability theory as a useful tool for answering some of the difficult questions which have faced appraisers, particularly in rapidly changing market conditions. Part 1 focused on the basics of a normal distribution and was particularly helpful in deciphering the ‘why’ behind what has been termed ‘the appraisal gap’. Part 2 delved a bit deeper into probability theory regarding skewed distributions, which has some practical implications regarding the reconciliation of the sales comparison. If you haven’t read those yet, I’d recommend reading them first.
Comparable Selection
In Part 2, I mentioned that “a good reconciliation can’t make up for a bad comparable selection.” While that may seem obvious, the ‘why’ question here is important. What do I even mean by a bad comparable selection? Although economic, legal, locational, and physical similarities are important, that is not what I am referring to in this case. What I am referring to is the variance between a comparable sales price and its value. Thus far we have taken a considerable amount of time demonstrating how and why prices and values often diverge, particularly in rapidly changing or erratic market conditions. It is possible to have a set of comparables which are very similar to the subject, but represent only one side of the distribution. See below for an illustration of this.
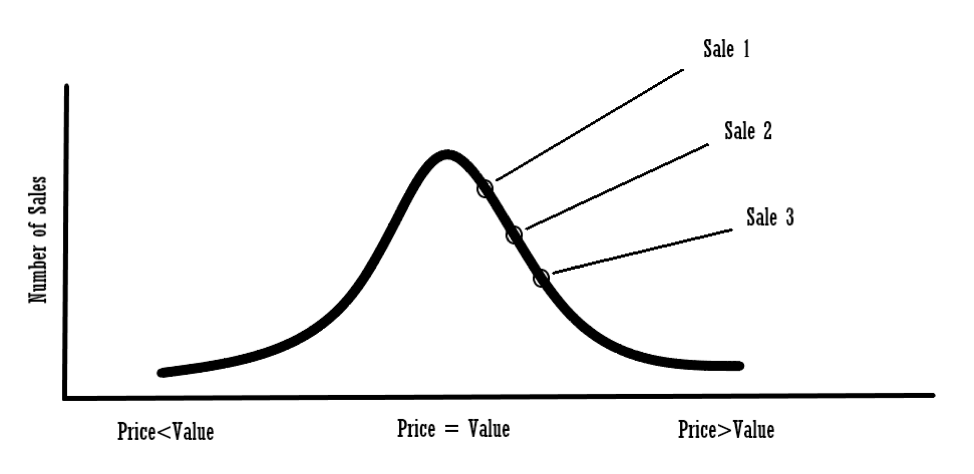
In this example, the appraiser has chosen 3 sales for the sales comparison approach, but all 3 sales are located at the high end of the distribution. Even if the analysis of these comparables is spot on, the result will still be skewed. Please note that this doesn’t necessarily mean a high unadjusted price. It is a high price relative to the value. This can be very difficult to determine at the outset, and nearly impossible if the appraiser chooses only a small number of comparables for analysis.
Quantity of Comparables
While the quality of comparables in terms of similarity to the subject is important, the quantity of comparables is equally important in order to avoid skewing the result. The more comparables chosen, the higher the likelihood that the comparables will be a representation of the subject’s market as a whole. The example below assumes that the same appraiser had chosen a wider selection of comparables in addition to the first three.

As you can see, the distribution doesn’t have to be perfect to see that the 7 sales in this example do a much better job of representing the market than did the first 3 alone.
Practical Implications
At this point, let me reiterate that I’m not trying to add more work. In fact, in my practice I have noticed that choosing a wider selection of comparables at the beginning makes every other part of the analysis move more quickly. I utilize an application, which imports data into my appraisal forms, which also makes adding more comparables quick and easy. If you aren’t already familiar with these programs, you would be wise to see what is available in your market. I have used both Spark and Datamaster and both are excellent applications. As a practical matter, I spend a lot less time pouring over the comparables at the outset. If it looks like it might be comparable at first glance, I drop it into the application and then spend more time looking closely once it is in my sales comparison grid. I probably import 9 comparables on my typical appraisal after only a few searches. One of the additional benefits of this method is in regard to adjustment support. When a larger set of data is considered, the sensitivity analysis is much more effective. This brings me to a much needed discussion regarding adjustment support.
Paired Sales
It’s probably the first analysis tool you learned in Appraisal 101…paired sales. In theory, paired sales makes perfect sense, but in practice, it can be unreliable. Why? Because, any single pair, while maybe the perfect pair on paper, may represent two different places on their respective distributions.

In this example we have two different distributions, one with a particular amenity and one without. With a single pair, we extract the value of the amenity based on the price difference between two otherwise identical properties. However, if one sale was toward the lower end of its distribution and the other sale toward the higher end of its distribution, the extracted value of the amenity may be very skewed from its actual contributory value which is best represented by the peak of each respective distribution.

Market Study
This is where a market study is helpful. A market study takes into account a broad enough set of data to make more reliable inferences about the distribution as a whole. There are generally two approaches to a market study:
The first is basically to start with paired sales, but to repeat the data pairing long enough to create a reliable measure of the central tendency of the price differential. In our illustration, that would mean having enough pairs out of each distribution so that the average line (labeled ‘Extracted Value of Amenity’) is equal to that of the line in the second illustration. The problem with this approach is that it can be hard enough to find a single ‘perfect’ pair, much less enough to create a reliable range.
The second approach is one which I utilize most often. It is to compare two entire data sets, not just a single data point from each data set. This solves the problem of skew, but does create other challenges, which we can look at more carefully in the future.
Conclusion
While this is the final article in this series, there are many other aspects of the appraisal which can benefit from thinking about your data in its larger context. While it may be helpful to change some practical aspects of your appraisal process, sometimes it is enough just to use probability theory to conceptualize your process. In either case, I hope that this has been a helpful introduction to what it can look like to apply these concepts to our industry.
Share this article
Written by : Brent Bowen
Brent is the president of Texas Valuation Professionals, Inc. (www.txvaluepro.com) in Plano, Texas and has been appraising residential real estate in north Texas for 25 years. He graduated from Baylor University with an enthusiasm for both economics and real estate, which made real estate appraisal a perfect fit. Rarely satisfied with the status quo, Brent hopes to always be open to further development, both professionally and personally.